
Speech recognition is classified into two categories, speaker dependent and speaker independent.
Speaker dependent systems are trained by the individual who will be using the system. These systems are capable of achieving a high command count and better than 95% accuracy for word recognition. The drawback to this approach is that the system only responds accurately only to the individual who trained the system. This is the most common approach employed in software for personal computers.
Speaker independent is a system trained to respond to a word regardless of who speaks. Therefore the system must respond to a large variety of speech patterns, inflections and enunciation's of the target word. The command word count is usually lower than the speaker dependent however high accuracy can still be maintain within processing limits. Industrial requirements more often need speaker independent voice systems, such as the AT&T system used in the telephone systems.
Recognition Style
Speech recognition systems have another constraint concerning the style of speech they can recognize. They are three styles of speech: isolated, connected and continuous.
Isolated speech recognition systems can just handle words that are spoken separately. This is the most common speech recognition systems available today. The user must pause between each word or command spoken. The speech recognition circuit is set up to identify isolated words of .96 second lengths.
Connected is a half way point between isolated word and continuous speech recognition. Allows users to speak multiple words. The HM2007 can be set up to identify words or phrases 1.92 seconds in length. This reduces the word recognition vocabulary number to 20.
Continuous is the natural conversational speech we are use to in everyday life. It is extremely difficult for a recognizer to shift through the text as the word tend to merge together. For instance, "Hi, how are you doing?" sounds like "Hi,.howyadoin" Continuous speech recognition systems are on the market and are under continual development.
Speech Recognition Circuit
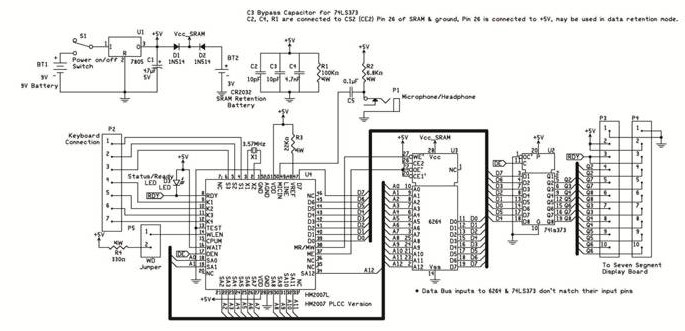
The demonstration circuit operates in the HM2007's manual mode. This mode uses a simple keypad and digital display to communicate with and program the HM2007 chip.
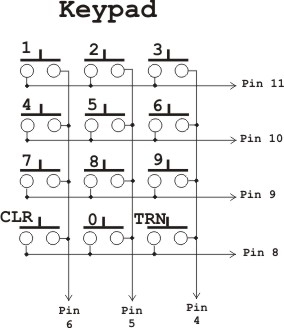
Keypad: The keypad is made up of 12 switches.
When the circuit is turned on, the HM2007 checks the static RAM. If everything checks out the board displays "00" on the digital display and lights the red LED (READY). It is in the "Ready" waiting for a command.
To Train
To train the circuit begin by pressing the word number you want to train on the keypad. The circuit can be trained to recognize up to 40 words. Use any numbers between 1 and 40. For example press the number "1" to train word number 1. When you press the number(s) on the keypad the red led will turn off. The number is displayed on the digital display. Next press the "#" key for train. When the "#" key is pressed it signals the chip to listen for a training word and the red led turns back on. Now speak the word you want the circuit to recognize into the microphone clearly. The LED should blink off momentarily, this is a signal that the word has been accepted.
Continue training new words in the circuit using the procedure outlined above. Press the "2" key then "#" key to train the second word and so on. The circuit will accept up to forty words. You do not have to enter 40 words into memory to use the circuit. If you want you can use as many word spaces as you want.
Testing Recognition
The circuit is continually listening. Repeat a trained word into the microphone. The number of the word should be displayed on the digital display. For instance if the word "directory" was trained as word number 25. Saying the word "directory" into the microphone will cause the number 25 to be displayed.
Error Codes
The chip provides the following error codes:
55 = word too long
66 = word too short
77 = word no match
Build a Speech Recognition Circuit page 3 "Training the HM2007"